Beyond code completion: Moving into the era of the autonomous agent.
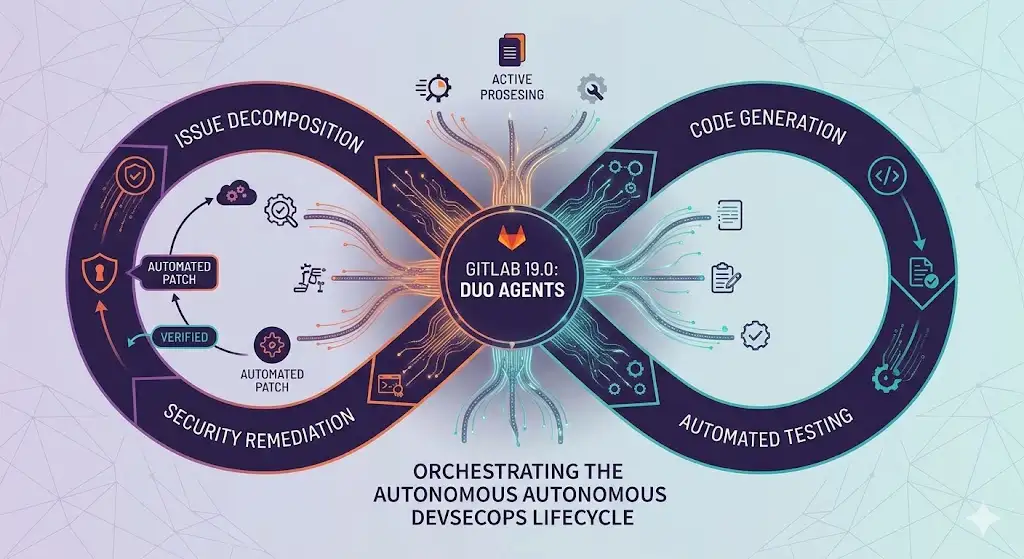
With the release of GitLab 19.0, the industry moves beyond simple code-completion prompts into the era of the autonomous agent. This update integrates GitLab Duo Agents across the entire software development lifecycle (SDLC), transforming GitLab from a passive repository and CI/CD tool into a proactive, agentic platform capable of reasoning, planning, and executing complex technical tasks.
Technical TL;DR
Autonomous Workflow Execution: Agents now handle end-to-end tasks, including issue decomposition, code generation, and automated testing.
AGENTS.md Implementation: Introduction of a standardized specification for defining project-level context, constraints, and operational boundaries for AI agents.
Context-Aware Reasoning: Utilizes localized repository metadata and RAG (Retrieval-Augmented Generation) to ensure agents understand complex microservice architectures.
Security-First Autonomy: Agents proactively identify vulnerabilities and generate production-ready patches for review within the CI pipeline.
Key Features/Benchmarks
GitLab 19.0 introduces Autonomous Merge Request (MR) Remediation, which has demonstrated a significant reduction in Mean Time to Remediation (MTTR). By leveraging underlying LLMs with specialized reasoning loops, the platform can now interpret security scan results and automatically commit fixes that adhere to the project’s specific linting and architectural patterns.
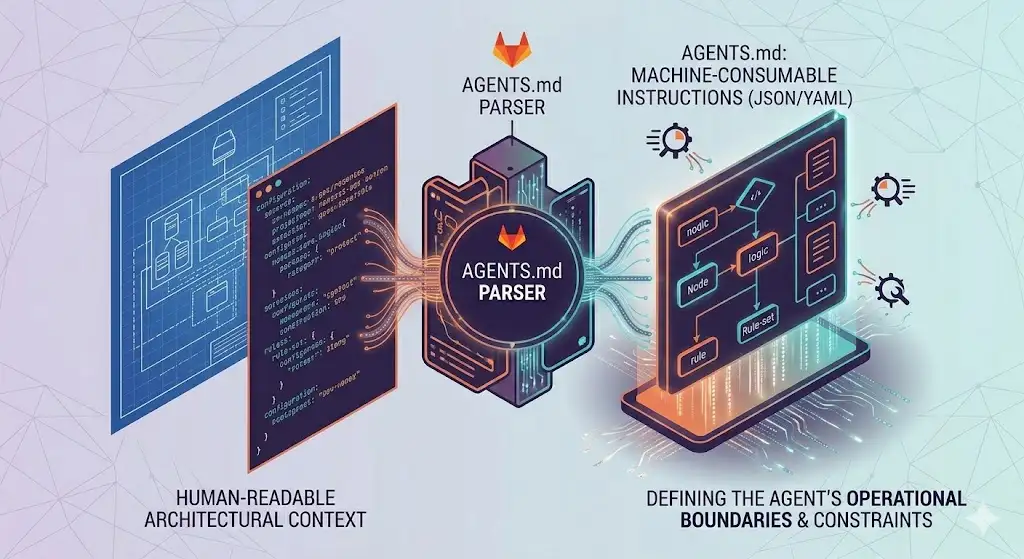
The cornerstone of this release is the support for AGENTS.md. Much like a README.md provides human-readable documentation, AGENTS.md provides machine-consumable instructions. This allows developers to define the “rules of engagement” for autonomous agents, specifying which libraries are preferred, which patterns are deprecated, and how the agent should navigate internal API dependencies.
Developer Impact
The shift in GitLab 19.0 fundamentally redefines the developer’s role from a “writer of syntax” to an “Agent Manager.” Technical expertise is no longer measured solely by the ability to produce lines of code, but by the ability to architect systems and document them so precisely that autonomous agents can navigate them effectively.
The introduction of AGENTS.md requires a new discipline in documentation. Developers must now master the art of structured architectural context, ensuring that the project’s mental model is transparent to the AI. As agents take over the heavy lifting of boilerplate, dependency updates, and routine security patching, developers are freed to focus on high-level system design and complex problem-solving, acting as the final bridge of accountability in an AI-driven pipeline.
Redefining the intersection of aerospace engineering and artificial intelligence.
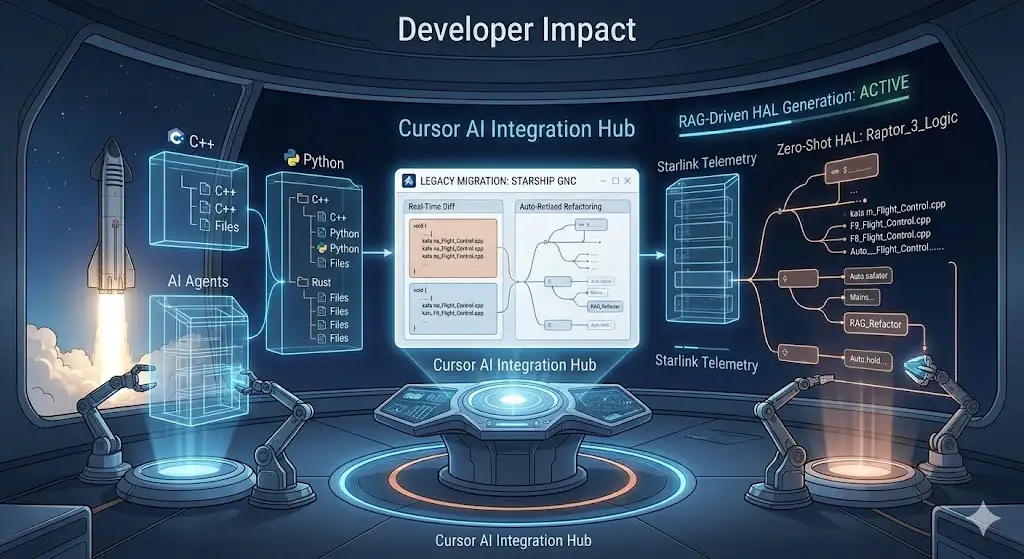
In a move that redefines the intersection of aerospace engineering and artificial intelligence, SpaceX has finalized its $60 billion acquisition of the AI-native coding platform, Cursor. This acquisition represents one of the largest software exits in history, signaling a fundamental shift toward autonomous software development in high-stakes, mission-critical environments.
Technical TL;DR
•Acquisition Value: $60 billion USD, reflecting a massive premium on AI-driven developer productivity tools.
•Strategic Objective: Integration of agentic IDE workflows into SpaceX’s proprietary flight software stacks and Starlink ground station telemetry.
•Core Technology: Leveraging Cursor’s “Composer” features and contextual RAG (Retrieval-Augmented Generation) to manage multi-million line C++ and Python codebases.
•Hardware-Software Co-design:Using AI to bridge the gap between rapid hardware prototyping and the software required to govern it.
Key Features/Benchmarks
The integration focuses on Cursor’s ability to maintain a deep contextual map of complex repositories. In internal SpaceX benchmarks, Cursor-driven workflows demonstrated a 40% reduction in the “Time to First Commit” for new engineers working on Starship’s flight control systems.
Contextual IntelligenceCursor’s ability to index entire local codebases allows for zero-shot generation of hardware abstraction layers (HALs).
Automated RefactoringReal-time migration of legacy flight code to memory-safe paradigms, reducing technical debt during rapid iteration cycles.
Aerospace-Grade AccuracyFine-tuning underlying Large Language Models (LLMs) on SpaceX’s proprietary telemetry data to predict edge-case failures in code logic before they reach the simulation phase.
Developer Impact
For the broader developer community, this acquisition validates the “AI-first” IDE as the primary interface for modern engineering. At SpaceX, the role of the software engineer is evolving from manual syntax entry to high-level architectural oversight.
Developers are now managing fleets of AI agents that handle boilerplate, testing, and documentation, allowing human engineers to focus on system-level logic and physics constraints.
As SpaceX pushes for full autonomy in its Mars program, the reliance on Cursor suggests that the future of aerospace—and perhaps all software engineering—will be defined by the speed at which developers can prompt, verify, and deploy AI-generated code.
Xiaomi has officially announced the open-source release of MiMo Code, a terminal-native AI assistant engineered to address the most persistent challenge in automated software engineering: long-horizon task execution. While traditional AI coding tools often suffer from “contextual amnesia” during extended sessions, MiMo Code maintains state-awareness across complex, multi-step workflows, enabling reliable repository-scale transformations.
Technical TL;DR
•Terminal-Native Architecture: Operates directly within the shell, providing deep integration with local compilers, debuggers, and version control systems.
•Long-Horizon Reliability: Specifically optimized to execute sequences exceeding 200 steps without losing track of the primary objective or architectural constraints.
•Amnesia Mitigation: Utilizes a proprietary state-tracking mechanism that prevents context drift, ensuring that the final line of code remains consistent with the initial project requirements.
•Multi-File Orchestration: Capable of performing cross-module refactors and managing dependencies across disparate directories simultaneously.
•Open-Source Core: Released to the community to foster transparency and allow for custom integration into specialized CI/CD pipelines.
Key Features & Benchmarks
MiMo Code distinguishes itself by solving the “context window decay” common in standard LLM implementations. In internal benchmarking, MiMo Code demonstrated a 40% higher success rate in multi-file refactoring tasks compared to existing terminal assistants. By utilizing an iterative feedback loop, the system validates each step against the project’s build system, automatically correcting syntax errors or logic mismatches in real-time. This “act-observe-correct” cycle allows it to navigate large codebases where the global state is too vast for a single inference pass.
Developer Impact
The release of MiMo Code marks a shift from reactive AI “chatbots” to proactive autonomous agents. For senior developers, this means the ability to delegate high-toil tasks—such as migrating a legacy codebase to a new framework or implementing comprehensive error handling across dozens of microservices—with high confidence. By operating natively in the terminal, MiMo Code fits seamlessly into existing developer environments (Vim, Tmux, Zsh), providing a sophisticated automation layer that respects the developer’s local configuration and security protocols. Rather than just generating snippets, MiMo Code functions as a persistent digital collaborator capable of seeing complex architectural changes through to completion.
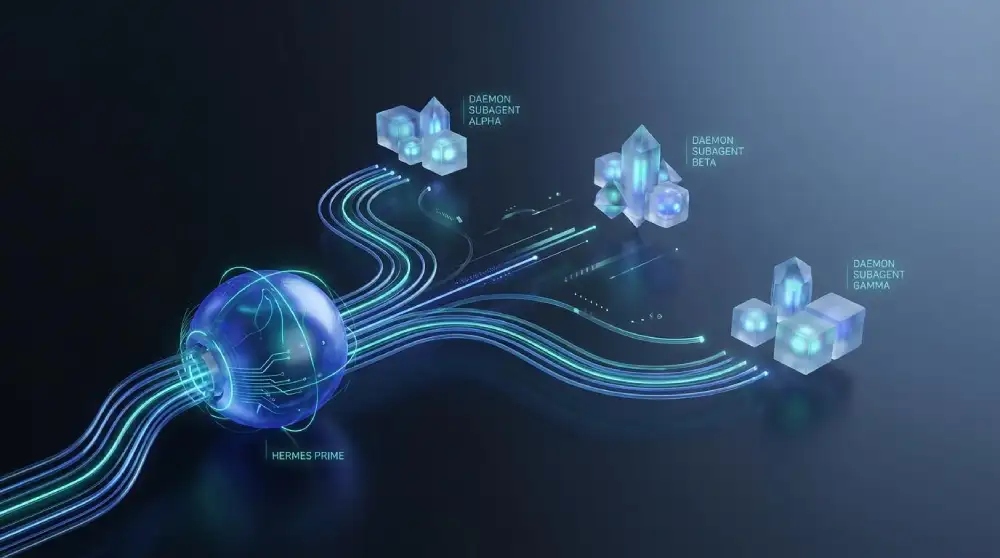
Nous Research has announced a significant upgrade to its open-source Hermes Agent framework, introducing asynchronous subagents for Hermes designed to handle complex background tasks without library-related interruptions to the primary user experience.
Architectural Shift: The Background Parameter
Announced by cofounder Teknium on Monday evening, the update addresses a critical bottleneck in agentic workflows: the latency caused by sequential task execution. The core of this update lies in the enhanced delegate_task tool. By utilizing the new “background=true” parameter, developers can now launch subagents in daemon threads.
“Developers have likened the new functionality to hiring an employee who works diligently in the background without holding up the boss.”
This architectural shift allows the framework to return a task handle in as little as two milliseconds, ensuring that the main chat interface remains fluid and responsive. Unlike traditional synchronous agents that force the “boss” agent (or the user) to wait for a task to complete, these asynchronous subagents operate independently in the background.
Enterprise-Grade Performance – SUBAGENTS FOR HERMES
Once a subagent finishes its assigned objective—whether it is deep-dive research, complex code reviews, or exhaustive log analysis—the results are pushed back to the main thread as comprehensive messages. These reports include the original goals, full context, and final execution status, providing a seamless audit trail of the work performed.
The developer community has responded to this news with enthusiasm, noting that the update effectively allows for true concurrency within AI-driven projects. Key use cases identified by early adopters include parallel research, where agents query multiple sources simultaneously, and per-file refactoring, where individual subagents analyze and modify multiple code files at once.
What is an LLM? A Large Language Model (LLM) is an advanced type of artificial intelligence designed to understand, interpret, and generate human-like text by processing vast datasets. At its simplest, an LLM acts as a highly sophisticated “auto-complete” tool. Having ingested billions of pages of public internet data, it uses that knowledge to predict the most mathematically probable next word in a sentence, allowing it to write essays, answer complex questions, and hold natural conversations.
From a technical perspective, a Large Language Model is a deep learning algorithm based on the Transformer architecture. It utilizes self-attention mechanisms to process input sequences in parallel, representing human language as high-dimensional vectors to perform probabilistic inference. These models are considered “large” due to their massive number of parameters—the internal neural connections that often number in the hundreds of billions—and the sheer volume of training data they consume.
The advent of Generative AI has sparked a technological revolution comparable to the invention of the internet or the smartphone. By granting machines the ability to process and produce natural language, LLMs are fundamentally transforming how businesses operate, how software is written, and how humans interact with digital information.
2. A Brief History of Language Modeling
The history of language modeling is defined by a rapid evolution from rigid, rule-based algorithms to deep learning models capable of advanced, generalized reasoning. Before the modern artificial intelligence boom, natural language processing relied heavily on statistical models like N-grams. These early systems simply counted how often words appeared together to predict the next word. While functional for basic spell-check, they lacked any true understanding of meaning or context.
To solve this, researchers developed Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks. These models represented a leap forward by processing text sequentially, reading sentences one word at a time. However, this sequential approach created a severe bottleneck. RNNs were incredibly slow to train and suffered from a “forgetting” problem; by the time the model reached the end of a long paragraph, it had lost the context of the opening sentence.
The landscape of artificial intelligence changed forever in 2017. Researchers at Google published a landmark paper titled “Attention Is All You Need,” which introduced the Transformer architecture. The Transformer abandoned sequential processing entirely, allowing models to look at an entire sentence or document simultaneously.
Following this breakthrough, 2018 saw the release of Google’s BERT (a bidirectional model revolutionizing search) and OpenAI’s GPT-1, which demonstrated the immense power of unsupervised pre-training. Between 2019 and 2022, the AI industry entered the “Scaling Era.” Developers realized that exponentially increasing the size of models—growing from GPT-2’s 1.5 billion parameters to GPT-3’s 175 billion—drastically improved their reasoning capabilities. By late 2022 and 2023, the integration of conversational alignment techniques birthed ChatGPT, catapulting Generative AI into the global mainstream.
3. How LLMs Work: Under the Hood
Large Language Models work by converting human language into mathematical representations and using deep learning networks to predict the next logical piece of a sequence. They do not “understand” words as humans do; rather, they calculate the complex statistical relationships between concepts.
Neural Network Basics
At their core, LLMs are built upon artificial neural networks, mathematical frameworks designed to loosely mimic the human brain. These networks consist of multiple layers of artificial “neurons” or nodes. When data enters the model, it passes through these layers via weighted connections. The model adjusts these weights—known as parameters—during training to minimize errors. A higher parameter count generally correlates with a model’s ability to capture higher complexity, nuance, and factual knowledge.
The Transformer Architecture and Self-Attention
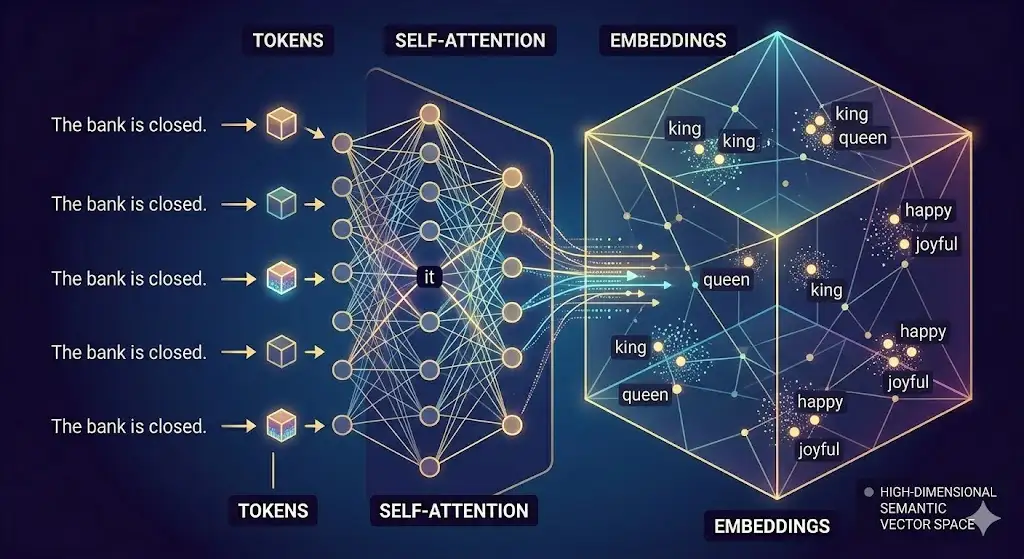
The secret engine driving every modern LLM is the Transformer architecture, specifically its “self-attention” mechanism. Self-attention allows the artificial intelligence to assign different levels of “weight” or importance to various words in a prompt, regardless of their position in a sentence.
For example, consider the sentence: “The bank was closed because it was a holiday.” In older models, the word “it” was difficult to parse. Through self-attention, the Transformer architecture analyzes the surrounding context and assigns a high attention weight connecting “it” to “bank,” rather than “holiday.” This mechanism enables the LLM to capture long-range dependencies and maintain deep contextual accuracy across massive documents.
Tokens and Embeddings
Computers cannot process letters or words; they can only process numbers. Therefore, before an LLM can read a prompt, the text must be broken down into “tokens.” A token can be an entire word, a syllable, or just a single letter.
Once tokenized, these fragments are converted into “embeddings.” Embeddings are high-dimensional mathematical vectors. In the model’s internal map, words with similar meanings (like “king” and “queen” or “happy” and “joyful”) are placed physically closer together in this mathematical space. This allows the LLM to understand semantic relationships and analogies through spatial geometry.
Context Windows
An LLM’s context window is its active memory span during a single conversation. It dictates how many tokens the model can “hold in its head” at one time. Early models had context windows of a few thousand tokens (roughly a few pages of text). Today, advanced models feature context windows of up to two million tokens, allowing users to upload entire books, codebases, or legal transcripts for the model to analyze in a single prompt without forgetting the initial instructions.
4. The Lifecycle of an LLM: Training and Tuning
The lifecycle of a Large Language Model consists of three primary stages: ingesting massive amounts of raw text to learn the mechanics of language, supervised fine-tuning to learn how to answer prompts, and human alignment to ensure the outputs are safe and helpful.
Phase 1: Pre-training
The first phase, pre-training, requires massive computational power and months of processing time. During this stage, the model is fed a vast corpus of human knowledge—typically terabytes of data scraped from Wikipedia, digitized books, GitHub repositories, and public websites.
This is a self-supervised learning process. The model is repeatedly shown a sequence of text with the final word hidden and is asked to predict it. At first, its guesses are random. But over trillions of iterations, it adjusts its parameters to reduce its error rate. By the end of pre-training, the model has learned grammar, syntax, facts, reasoning, and the general statistical structure of language. However, at this point, it is just a document-completion tool; if you prompt a pre-trained model with “What is the capital of France?”, it might respond with “What is the capital of Germany?” rather than answering the question.
Phase 2: Instruction Fine-Tuning
To transform the base model into a useful Generative AI assistant, it must undergo Supervised Fine-Tuning (SFT). Researchers expose the model to highly curated datasets consisting of “Instruction-Response” pairs. By studying thousands of examples of questions followed by accurate, well-formatted answers, the LLM shifts its behavior. It learns that its purpose is no longer to seamlessly continue a document, but to fulfill commands, write poetry, generate code, or summarize data based on the user’s explicit instructions.
Phase 3: RLHF (Reinforcement Learning from Human Feedback)
The final stage bridges the gap between a capable model and a safe, conversational one. Reinforcement Learning from Human Feedback (RLHF) aligns the LLM with human values. Human evaluators are given multiple responses generated by the model for a single prompt and are asked to rank them based on helpfulness, accuracy, and safety.
These human preferences are used to train a separate “Reward Model,” which then automatically scores the LLM’s outputs during further training. The LLM is optimized to generate the types of responses that yield the highest reward scores. This critical phase is what stops the model from generating toxic content, teaches it to refuse harmful requests, and gives modern AI chatbots their remarkably polite and helpful conversational tone.
5. Key Metrics: Parameters and Performance
Parameters are the fundamental numerical variables—the internal weights and biases—that a Large Language Model adjusts during training to determine how it processes information and makes predictions. In the context of neural networks, you can think of parameters as millions or billions of microscopic “knobs and dials.” Whenever a model learns a new fact, grammar rule, or reasoning pathway, it physically adjusts the mathematical value of these dials to minimize its error rate.
Historically, the AI industry operated under the assumption that increasing a model’s parameter count automatically resulted in superior intelligence. This drove the creation of massive models boasting hundreds of billions, or even trillions, of parameters. However, modern AI research has revealed that bigger does not always mean better. Performance is deeply tied to the quality, diversity, and density of the training data. A highly optimized model with 70 billion parameters trained on meticulously curated, high-quality data can often outperform a model with 300 billion parameters trained on low-quality, repetitive internet scrapings. As the industry matures, the focus has shifted from simply inflating parameter counts to improving data quality, training efficiency, and architectural optimization.
6. Comparison of Leading LLMs in 2026
The leading Large Language Models in the current market include OpenAI’s GPT-5, Anthropic’s Claude 4.8, Meta’s Llama 3.1/4, and Google’s Gemini 2.5/3.1. each offering distinct advantages in reasoning, context limits, and accessibility. Choosing the right LLM depends entirely on the specific use case, budget, and deployment requirements of the user or enterprise.
Claude remains an industry benchmark with models like Claude Opus 4.6 and its iterative updates, which excel as “all-rounders” capable of deep logical reasoning and dynamic problem-solving. Anthropic’s Claude has carved out a massive user base by prioritizing nuanced, safe responses and demonstrating superior capabilities in software engineering and coding tasks. Google’s Gemini series differentiates itself through native multimodality—processing text, audio, and video simultaneously without external translation layers—and massive context windows reaching up to two million tokens.
Comparison of Leading Large Language Models
7. LLM Applications: How the World Uses AI
Generative AI applications span a vast array of industries, revolutionizing how professionals write code, generate business content, analyze complex data, and interact with customers. By seamlessly processing human language, LLMs are acting as cognitive engines powering hundreds of modern software solutions.
Software Engineering and Coding
LLMs have fundamentally changed the software development lifecycle. Developers use AI to instantly generate boilerplate code, write unit tests, and translate legacy codebases from one language to another (such as migrating outdated Python scripts to C++). Furthermore, models serve as real-time debugging assistants, identifying logic errors in complex code arrays much faster than manual review.
Business and Customer Support
In the corporate sphere, advanced AI chatbots have largely replaced the rigid, decision-tree chatbots of the past. Modern customer support LLMs can understand frustrated customers, reference internal knowledge bases, process refunds, and generate highly personalized responses. Businesses also utilize Retrieval-Augmented Generation (RAG) frameworks, allowing them to connect an LLM to their private corporate databases for secure, real-time data querying.
Content Creation and Marketing
For writers, marketers, and legal professionals, LLMs are unparalleled drafting tools. They are routinely used to generate marketing copy, outline blog posts, draft routine legal contracts, and synthesize long, convoluted reports into bulleted executive summaries. This drastically reduces the time professionals spend on the blank-page phase of creation.
Education, Science, and Data Analysis
In scientific research and education, LLMs excel at extracting structured data from massive troves of unstructured text. Researchers use them to run sentiment analysis on millions of public reviews, summarize hundreds of academic papers simultaneously, and act as personalized, interactive tutors that can adapt their teaching style to a student’s specific learning pace.
8. Limitations, Ethics, and Risks
Despite their immense capabilities, Large Language Models face critical limitations and risks, including factual hallucinations, ingrained societal biases, and severe environmental impacts due to their high computational demands. Addressing these issues is the primary focus of modern artificial intelligence ethics.
Hallucinations and Accuracy
Because LLMs are probabilistic rather than deterministic, they do not inherently know what is true; they only know what is mathematically likely. This leads to “hallucinations,” where the model confidently generates fabricated facts, fake academic citations, or incorrect historical dates simply because the text output mathematically fits the pattern of the prompt.
Bias and Toxicity
LLMs are trained on human data, which means they inherit all human prejudices. Without rigorous RLHF and human alignment, models can easily generate biased outputs regarding race, gender, religion, and politics. Ensuring that these models remain neutral and safe, without crossing into extreme censorship, is a highly debated topic in artificial intelligence ethics.
Sustainability and Data Privacy
The environmental footprint of training and running LLMs is staggering. Data centers require massive amounts of electricity and millions of gallons of water for cooling to sustain the GPUs powering these models. Additionally, data privacy remains a significant risk; employees pasting sensitive, proprietary corporate data into public LLM interfaces risk exposing trade secrets to external training pipelines.
9. The Future of Large Language Models
The future of Large Language Models is defined by a rapid transition toward agentic AI workflows, native multimodality, and highly efficient Small Language Models (SLMs). Instead of merely answering questions, the next generation of models will take direct action on behalf of users.
Agentic AI
Future AI will operate as “Agents.” Rather than just writing a script for a user, an agentic LLM will be given a high-level goal, browse the internet for information, use third-party software tools, write its own code, execute that code, and complete multi-step workflows entirely autonomously.
Multimodality and SLMs
Models are increasingly becoming natively multimodal, meaning they process vision, audio, text, and robotics data simultaneously from the ground up. Simultaneously, the rise of Small Language Models (SLMs) is democratizing access. These highly efficient, compact models require vastly less computing power, allowing them to run locally and offline on smartphones and laptops, ensuring strict user privacy and zero latency.
10. Conclusion
Large Language Models represent a foundational shift in the history of computing, moving technology away from rigid, syntax-heavy programming and toward intuitive, natural language understanding. By turning the vast expanse of human knowledge into navigable mathematical space, LLMs have democratized access to high-level analysis, coding, and creative generation. While challenges regarding bias, hallucinations, and environmental impact remain, the continuous refinement of these models promises a future where artificial intelligence acts as an accessible, highly capable cognitive partner for every digital endeavor.
11. FAQ Section
What does LLM stand for?
LLM stands for Large Language Model, a type of artificial intelligence designed to understand and generate human language using deep neural networks and massive datasets.
Is an LLM the same as ChatGPT?
No. The LLM (such as GPT-4) is the underlying algorithmic engine, whereas ChatGPT is the user-facing chat application built on top of that engine.
Do LLMs think?
No. LLMs do not possess consciousness, true comprehension, or the ability to think. They perform highly complex statistical calculations to predict the most probable sequence of words.
Why do LLMs make mistakes?
LLMs are probabilistic. They predict what word should come next based on patterns in their training data. Sometimes, the most mathematically probable next word is factually incorrect, leading to a “hallucination.”
What is an LLM context window?
A context window is the model’s short-term memory limit for a single conversation. It determines how much text (measured in tokens) the model can analyze and remember at one time.
Can LLMs run offline?
Yes. While massive models require cloud infrastructure, smaller, highly optimized models (Small Language Models or SLMs) can be downloaded and run locally on personal laptops and smartphones without an internet connection.
What is RAG in the context of LLMs?
RAG stands for Retrieval-Augmented Generation. It is a technique where an LLM is securely connected to an external database (like a company’s internal documents), allowing the model to search that specific data to provide accurate, customized answers.
12. Citations/References
AWS AI Insights. “What are Large Language Models?” Amazon Web Services.
Google DeepMind Blog. “The Transformer Architecture and Next-Generation AI.”
IBM Research. “Understanding Large Language Models and Enterprise Governance.”
OpenAI Documentation. “GPT Models, RLHF, and AI Alignment.”
TechTarget. “Definition: Large Language Model (LLM).”
Moonshot AI has officially launched Kimi K2.7 Code HighSpeed, a high-performance variant of its latest open-source multimodal coding model. This update marks a substantial leap in efficiency, offering developers and enterprises a significantly faster interface for complex programming tasks and real-time code generation.
Revolutionizing Processing Velocity
The core achievement of Kimi K2.7 Code HighSpeed lies in its remarkable processing velocity. The model is now capable of operating at speeds up to six times faster than previous iterations, representing a major breakthrough in the field of AI-assisted software development.
“For standard coding tasks with median-length inputs, the system maintains a steady output of approximately 180 tokens per second. In shorter-context scenarios, performance peaks at 260 tokens per second.”
Access and Future Development
The rollout of this high-speed mode is currently targeted at a strategic group of stakeholders, including members of the Kimi Code Beta Program, Kimi API developers, and Kimi Business users. While the company has opted for a phased rollout due to current hardware capacity constraints, it has clarified that no formal invitation is required to join the queue.
This release aligns with Moonshot AI’s broader mission to ensure that open intelligence remains instant, affordable, and borderless. By prioritizing speed without sacrificing the multimodal capabilities of the K2.7 architecture, the company aims to reduce the friction between human intent and machine execution.
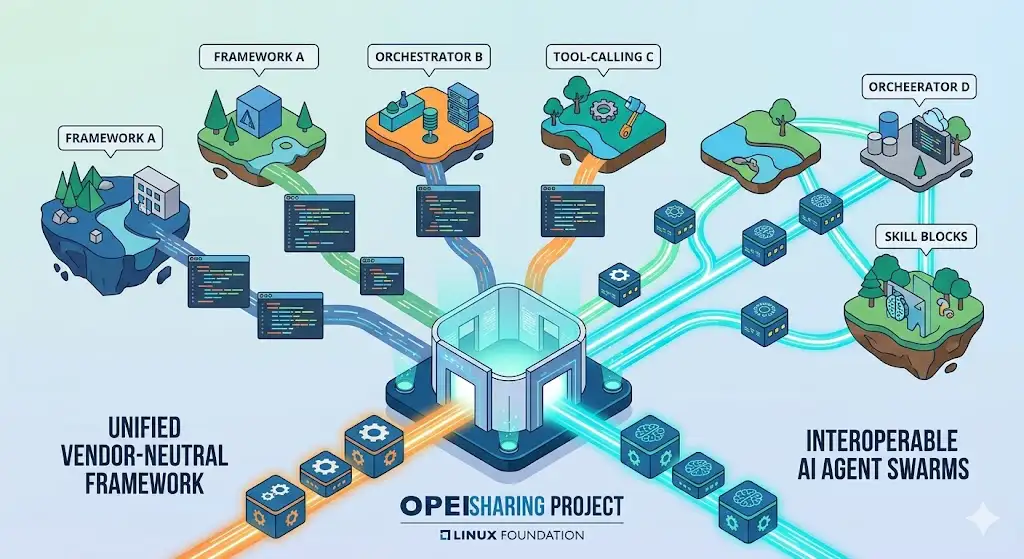
The Linux Foundation has officially announced the OpenSharing Project, a collaborative initiative aimed at establishing a unified, vendor-neutral framework for AI agent capabilities. As the industry shifts from monolithic LLM applications toward modular, multi-agent systems, the OpenSharing Project addresses the critical need for standardized “skill” definitions. This initiative seeks to bridge the architectural fragmentation currently hindering the deployment of autonomous swarms, ensuring that agentic tools remain interoperable regardless of the underlying model or runtime environment.
Technical TL;DR
Objective: Establish a universal protocol for defining, discovering, and executing AI agent skills across distributed systems.
Core Stack: Utilizes gRPC and Protocol Buffers (Protobuf) for high-performance communication, alongside JSON-Schema for strongly typed, human-readable skill manifests.
Interoperability: Facilitates seamless capability sharing between frameworks like LangChain, AutoGen, and CrewAI via a standardized API layer.
Security & Observability: Implements mTLS for secure skill invocation and integrated support for OpenTelemetry to track execution metrics.
Key Features/Benchmarks
The cornerstone of the project is the Skill Schema Specification (S3). This declarative format allows developers to define tool logic, required parameters, and output constraints in a machine-readable manifest.
Dynamic Discovery Protocol (DDP): Implements a decentralized registry system, allowing agents to query and bind to capabilities in real-time.
Execution Sandboxing: Defines a Wasm-based (WebAssembly) execution environment, ensuring skills remain portable and isolated within a “deny-by-default” security model.
The “Agentic Latency” Benchmark: Introduces a new standardized metric to measure the overhead of multi-hop skill invocation.
Developer Impact
For the engineering community, the OpenSharing Project represents a departure from proprietary silos. By decoupling skill logic from specific orchestrators, developers can drastically reduce the “shim code” and technical debt associated with refactoring tool-calling logic. This standardization enables a “write once, deploy anywhere” approach to agentic tools.
The open-source landscape has reached a significant milestone as “opencode,” the autonomous AI coding agent, officially surpassed 173,000 stars on GitHub. This rapid adoption signals a shift in developer preference toward transparent, extensible tools over closed-source, proprietary alternatives.
Technical TL;DR
●Architecture: Leverages an agentic workflow capable of multi-step reasoning, iterative self-correction, and autonomous file system manipulation.
●Language Support: Extends beyond standard syntax completion to provide deep semantic understanding for 40+ languages, including Rust, Go, and TypeScript.
●Integration: Native compatibility with the Language Server Protocol (LSP), enabling seamless integration with VS Code, JetBrains, and Vim/Neovim.
●Contextual Awareness: Features a sophisticated Retrieval-Augmented Generation (RAG) pipeline that indexes local repositories to provide project-specific logic suggestions.
●Security: Supports local-first execution, allowing developers to run the agent against private codebases without external data exfiltration.
Key Features and Benchmarks
“opencode” distinguishes itself by functioning as a true software engineering agent rather than a simple autocomplete engine. It excels in complex, non-linear tasks that require cross-file coordination.
Autonomous Debugging
High resolution rates on SWE-bench, identifying and fixing regressions across modules.
Refactoring Engine
Executes system-wide architectural changes while adhering to project-specific linting rules.
Test Generation
Automates unit and integration tests, focusing on edge cases and boundary conditions.
Performance
Benchmarks indicate a 40% reduction in “Time to First PR” for unfamiliar codebases.
Developer Impact
The rise of opencode is a critical development for the engineering community. It provides a high-quality, community-driven alternative to proprietary tools, fostering transparency and preventing vendor lock-in for AI-assisted development. By utilizing an open-source core, teams can audit the underlying logic, contribute to the tool’s evolution, and maintain full control over their development environment.
This movement toward open-source AI ensures that state-of-the-art coding assistance remains accessible, auditable, and customizable, allowing developers to build without the constraints of subscription-based gatekeeping or opaque data policies.
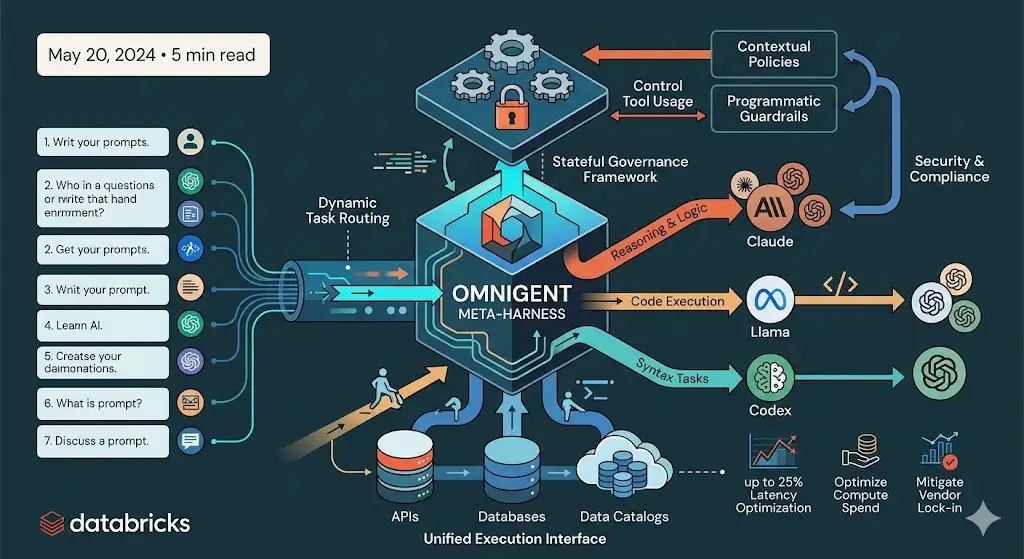
Omnigent addresses the limitations of monolithic LLM implementations by facilitating “agentic modularity.” Key technical features include:
Dynamic Task RoutingA sophisticated routing engine evaluates the requirements of a sub-task and dispatches it to the most efficient model. This prevents the over-utilization of expensive frontier models for deterministic tasks, significantly optimizing compute spend.
Stateful Governance FrameworkBeyond simple input/output filtering, Omnigent maintains a contextual state across multi-turn agent interactions. This allows for real-time enforcement of policies that prevent unauthorized tool calls or data exfiltration.
Unified Execution InterfaceIt standardizes how agents interact with external APIs and databases, providing a consistent abstraction layer that simplifies the management of tool-use and function-calling across different model families.
Latency OptimizationBenchmarks suggest that by offloading specialized sub-tasks to smaller, tuned models via the Omnigent harness, developers can achieve up to a 25% reduction in end-to-end latency compared to single-model chains.
Developer Impact
For AI engineers, Omnigent represents a shift from fragile, prompt-dependent scripts to robust, architectural choreography. By providing a meta-harness, Databricks enables developers to mitigate vendor lock-in; teams can swap underlying models as the SOTA evolves without re-architecting the entire agentic workflow.
Furthermore, the introduction of contextual policies solves the primary barrier to enterprise agent adoption: predictability. Developers can now programmatically define the “sandbox” in which an agent operates, ensuring that autonomous actions remain within the bounds of corporate governance. Omnigent essentially provides the plumbing and the policing required to move AI agents from experimental notebooks into production-grade environments.
Technical TL;DR
Architectural Role: Omnigent serves as a high-level coordination layer—a “meta-harness”—that decouples agentic logic from underlying model inference, allowing for heterogeneous model pipelines.
Multi-Model Orchestration: It enables the seamless integration of specialized models within a single workflow, such as utilizing Claude for complex reasoning and logic while delegating code execution or syntax-heavy tasks to Llama or Codex.
Policy-Driven Governance: The framework introduces “Contextual Policies,” which act as programmatic guardrails to enforce security, compliance, and operational boundaries on autonomous agents.
Ecosystem Integration: Designed to mitigate fragmentation, Omnigent provides a unified interface for agent composition that integrates with existing data catalogs and observability tools.
The landscape of accessible artificial intelligence shifted today with the launch of GLM-5.2, the latest flagship model designed by Z.ai to empower the global developer community. Built on the principle that intelligence should be open and ready for immediate deployment, GLM-5.2 arrives as a high-performance solution tailored for complex coding tasks and massive data processing.
Immediate Availability and Enhanced Developer Tools
GLM-5.2 has been officially integrated into all GLM Coding Plan tiers, including the Lite, Pro, Max, and Team versions. Developers currently utilizing these plans can access the model immediately through the latest development packages. This rollout ensures that teams of all sizes—from individual hobbyists to enterprise-level organizations—have the tools necessary to build sophisticated applications using the most advanced iteration of the GLM architecture to date.
Unprecedented Context and Coding Prowess
“As the new flagship of the series, GLM-5.2 introduces several critical technical upgrades. Most notably, the model features a usable 1-million-token context window.”
Beyond its expansive memory, GLM-5.2 is optimized for “long-horizon tasks”—complex operations that require sustained logic over many steps. These capabilities, combined with refined coding intelligence, position the model as a primary competitor in the field of automated software development and technical problem-solving.
The Path to Open Source
In a move that underscores a commitment to the “open future of AI,” the developers behind GLM-5.2 have announced a rapid expansion of the model’s accessibility. While currently restricted to coding plan users, API access and dedicated chatbot services are scheduled to launch next week.
Furthermore, the model will be officially open-sourced next week under the MIT License. By opting for one of the most permissive software licenses available, the GLM team aims to foster a collaborative environment where the global community can inspect, modify, and build upon the model’s architecture.